Moats in Markets That Didn't Exist 5 Years Ago
Anthropic's annualized revenue went from $1B to $30B in 18 months. OpenAI raised $110B in a single round. Traditional moat frameworks were built for businesses that existed five years ago. This week we rebuild the moat framework from scratch for AI-native companies.

Moats in New Tech
The classical moat framework — network effects, switching costs, cost advantage, intangible assets, efficient scale — was developed by studying businesses that had already existed for decades. The analyst could look at 30 years of financial statements, 30 years of market share data, 30 years of competitive entry attempts, and reach confident conclusions about which moats were durable and which were cyclical.
That luxury does not exist for the businesses currently reshaping the largest industries in the world.
Anthropic's annualized revenue went from $1B at end-of-2024 to $9B at end-of-2025 to $30B by April 2026 — a 30x jump in roughly 15 months. OpenAI just closed a $110 billion funding round at an $852 billion valuation. Tesla has accumulated approximately 9 billion miles of real-world driving data and is running them through a fleet that nobody else has access to. Each of these is arguably building a moat in a category that did not meaningfully exist five years ago. And each of them is being valued by capital markets today as if the moat is real, even though no traditional framework can confirm it yet.
This is the hard problem of new-technology moat analysis. You cannot wait for 20 years of ROIC data — by the time that data exists, the category leaders have already been decided and the stocks have already moved. You have to read the moat from behavioral and structural signals, while the business is still being built, and make an investment decision on evidence that a traditional analyst would consider incomplete. This week we cover how.
Core Framework: The Four Categories of New-Tech Moats
Most new-technology moats fit into one of four archetypes. Each is recognizable early, if you know what to look for, and each has a specific pattern of how it forms and how you tell if it is forming for this company versus just forming for the category.
| Category | What It Looks Like Early | Why It Becomes a Moat Later |
|---|---|---|
| Data network | Proprietary data that improves the product as usage scales | Each new user adds training/feedback that competitors cannot replicate |
| Platform ecosystem | Third-party developers building on top of your API/SDK | Switching cost compounds as ecosystem grows |
| Regulatory-gated scale | Compliance complexity, safety track record, certified integrations | New entrants cannot meet the regulatory bar quickly |
| Deep vertical integration | Owning more of the stack (chips, infrastructure, end-product) | Cost and capability advantages compound at scale |
All four are variants of the five classical moats, translated into the dynamics of fast-moving technology categories. A data network moat is a network effect. A platform ecosystem is switching costs combined with network effects. Regulatory-gated scale is intangible assets plus efficient scale. Deep vertical integration is cost advantage.
The reason these deserve their own framework is that the time-to-evidence is much shorter than in classical cases. A 30-year database of financial statements will not tell you whether Anthropic or OpenAI has a more durable enterprise moat. You need to read behavioral signals from what is happening now.
The Case: Anthropic vs OpenAI, Early 2026
Both companies are building AI foundation models. Both have strong research teams. Both sell API access to developers and enterprises. As of early 2026, both are at roughly similar scale on surface metrics. But their moat profiles are diverging sharply, and reading the divergence is a masterclass in new-tech moat analysis.
Revenue and valuation snapshot — April 2026
| Metric | Anthropic | OpenAI |
|---|---|---|
| Annualized revenue (ARR) | ~$30B | ~$25B |
| ARR growth (past 15 months) | ~30x | ~4x |
| Enterprise % of revenue | Majority | ~40% (consumer-heavy) |
| Largest product | Claude Code (~$2.5B ARR) | ChatGPT (consumer subscription) |
| Weekly active users | Not disclosed (enterprise-centric) | ~900M weekly active (consumer) |
| Enterprise customers spending >$1M/year | 1,000+ (up from 500 in February) | Not publicly disclosed at that tier |
| Most recent valuation | $380B (Series G, Feb 2026); $800B+ secondary | $852B post-money (Feb 2026, $110B round) |
Where Their Moats Diverge
Read those rows carefully. Revenue is roughly comparable. Valuation is roughly comparable. But the composition is very different, and that composition tells you almost everything about what kind of moat each is building.
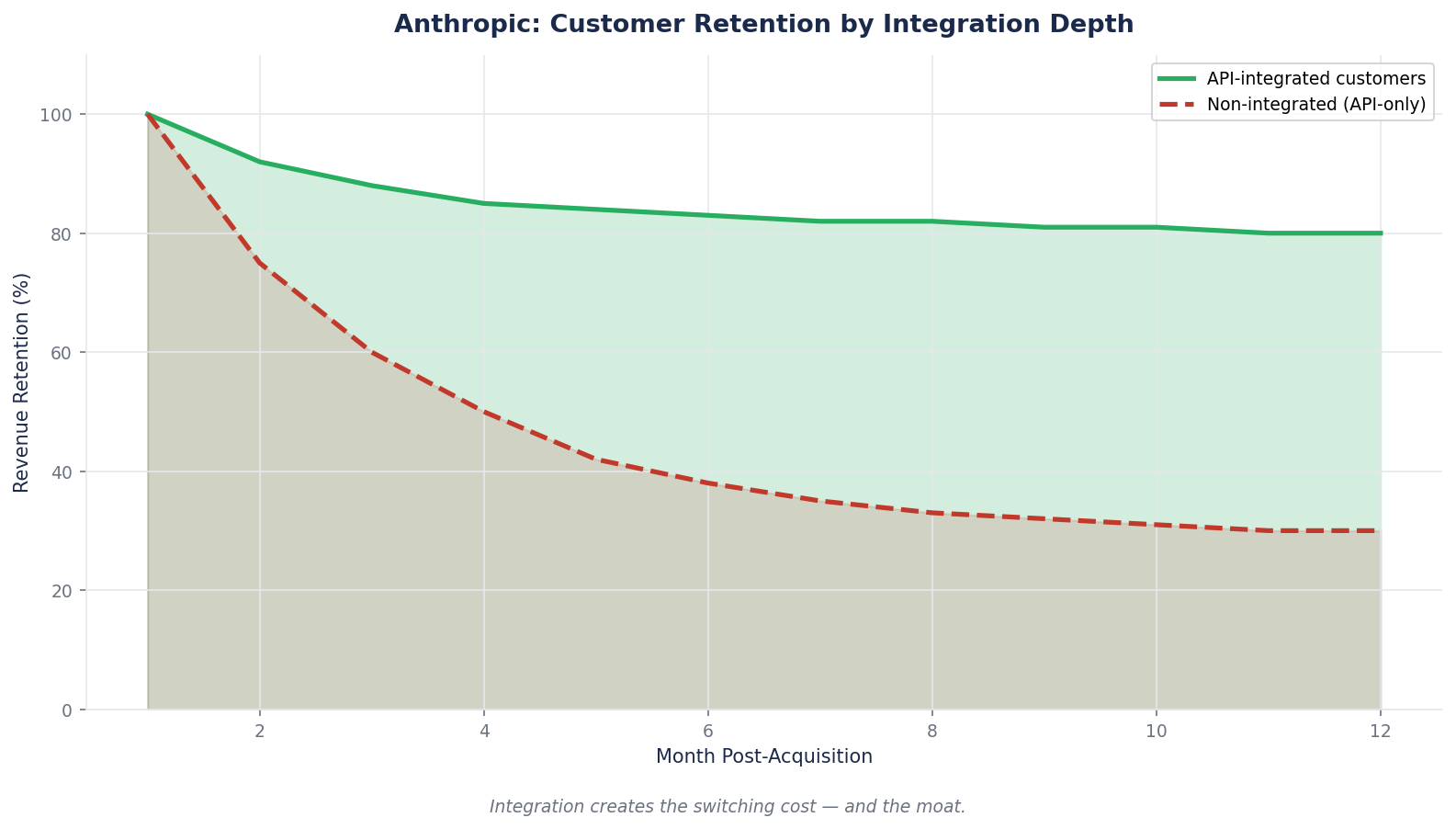
Anthropic is optimizing for enterprise API consumption and developer tools. Claude Code alone runs at a $2.5B ARR and accounts for approximately 4 percent of all public GitHub commits globally. The company's enterprise LLM API share grew from ~12% (mid-2025) to ~32% (early 2026). Eight of the Fortune 10 are customers. Among U.S. businesses tracked by Ramp Economics Lab, Anthropic's share of combined OpenAI-plus-Anthropic enterprise spend went from roughly 10 percent to over 65 percent in 14 months.
OpenAI is optimizing for consumer scale and brand. ChatGPT has approximately 900 million weekly active users. The product is the most-recognized AI application in history. Revenue mix is tilted toward consumer subscriptions, though enterprise is growing. OpenAI's enterprise LLM API share dropped from ~50% (2023) to ~25% (mid-2025) over the same window Anthropic rose. Sam Altman declared a company-wide "code red" in December 2025 specifically to accelerate enterprise and developer response.
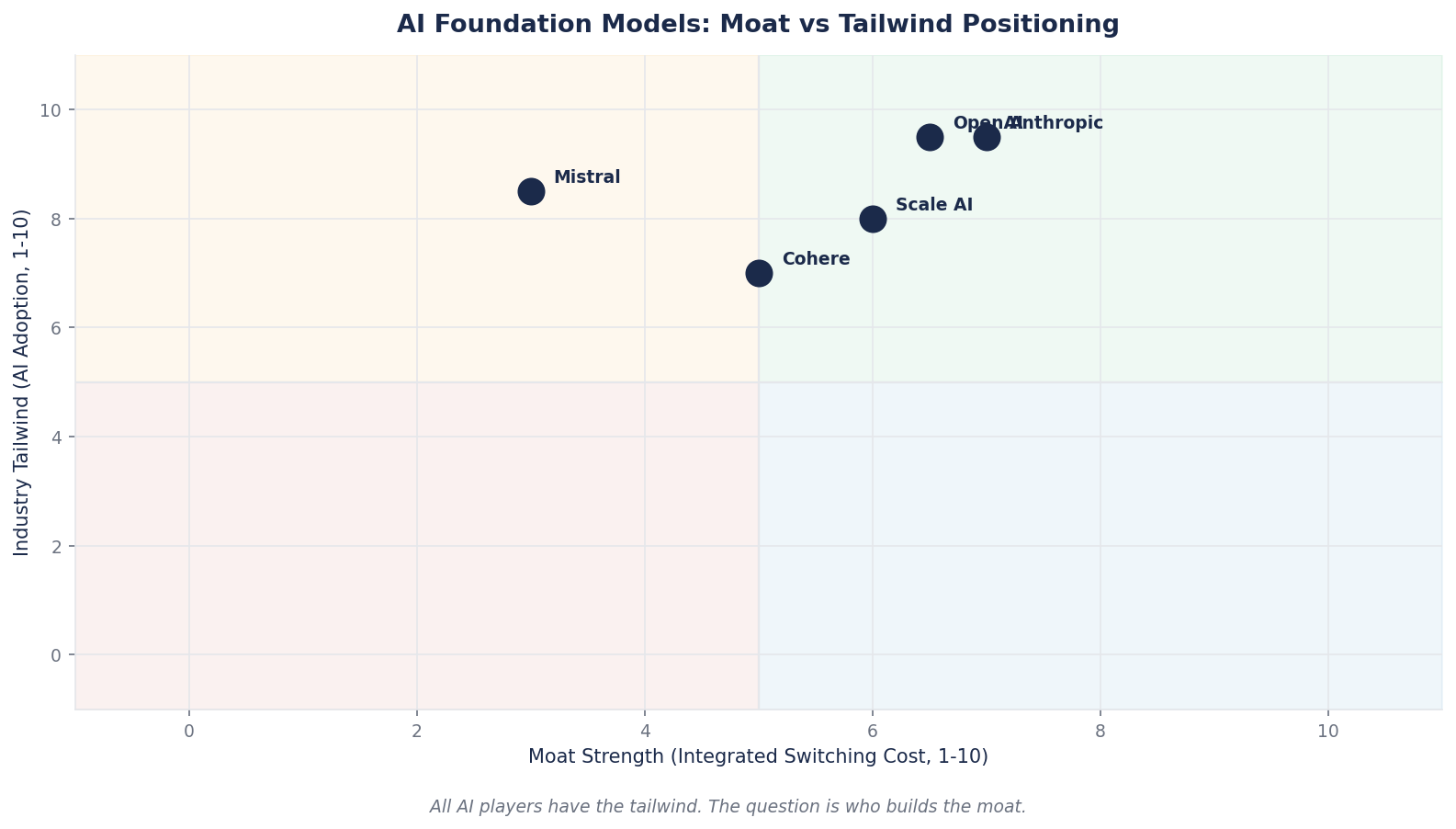
Mapping Each to a Moat Category
Apply the four-category framework:
| Moat Category | Anthropic Position | OpenAI Position |
|---|---|---|
| Data network | Enterprise deployment data (Claude in Fortune 10 workflows) | Consumer conversation data (900M weekly users) |
| Platform ecosystem | Claude Code (54% share of AI coding tools), MCP protocol as developer standard | GPT Store, plugins, custom GPTs |
| Regulatory-gated scale | Constitutional AI + Responsible Scaling Policy + Public Benefit Corp structure; first choice for healthcare (HIPAA-ready), finance, regulated industries | Less emphasis; more generalist positioning |
| Deep vertical integration | Multi-cloud (AWS Trainium, Google TPUs, NVIDIA GPUs) to match workloads | Heavier dependence on Microsoft / NVIDIA stack |
Two different moat profiles, different strategic bets. Neither is obviously wrong. What matters for an investor is recognizing that they are different kinds of bet — and that a retail investor who treats "OpenAI vs Anthropic" as interchangeable "AI stocks" is failing to price what is actually being purchased.
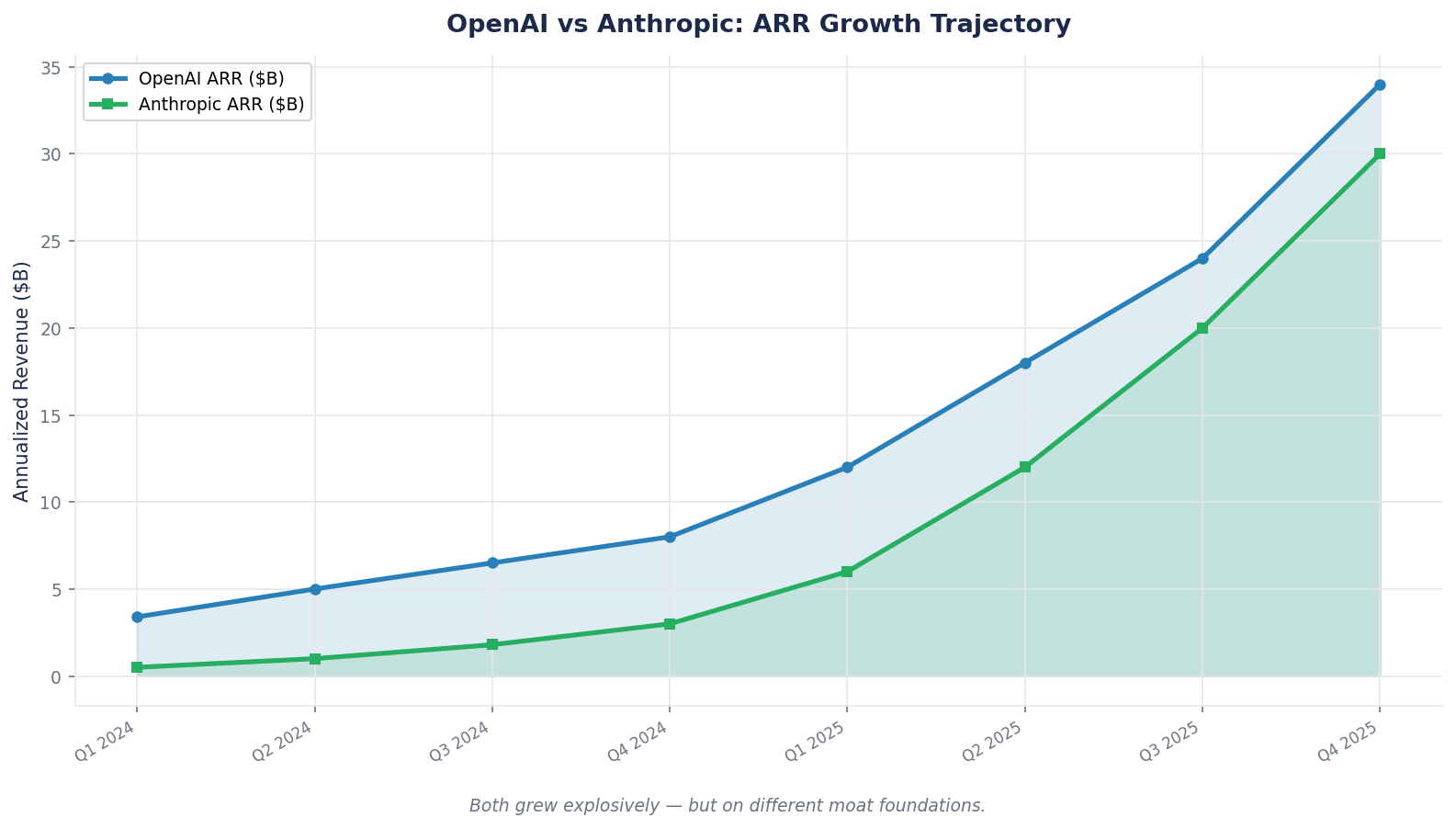
The Enterprise Stickiness Test
Here is the single strongest moat signal visible in the Anthropic numbers: the customer count at the high spending tier doubled in two months. From 500 enterprise customers spending >$1M annually (February 2026) to over 1,000 (April 2026).
That pattern is impossible without structural stickiness. Enterprise contracts at that spending level are not impulse decisions. They involve procurement, legal review, security assessment, integration planning, and pilot testing. The fact that the count doubled in two months means contracts signed 3–6 months earlier are now converting to spending, and the conversion rate itself is accelerating.
This is the behavioral signal you look for in a data-network or platform-ecosystem moat: not just that revenue is growing, but that the commitment depth is growing. Enterprise customers running Claude 10 million API calls per month because it replaced an internal team are not going to switch to a competitor based on a small price change. The integration, the workflow adaptation, the operational muscle memory — all of that is switching-cost formation happening in real time.
The Tesla Case: Data Network Moat Under Construction
Anthropic and OpenAI are pure software plays. Tesla is a more contested case: it is claiming a data-network moat in a physical-world application (autonomous driving) where the moat-test evidence is contested in both directions.
Tesla's claim:
- Approximately 9 billion miles of real-world FSD driving data accumulated
- Fleet of millions of vehicles continuously generating new data
- 456,000 paid FSD subscribers (as of recent disclosures), generating roughly $45M/month in subscription revenue
- Vertical integration: in-house silicon design (custom HW4 / HW5), in-house training infrastructure, in-house manufacturing
What a data-network moat requires to be real:
1. Scale that cannot be replicated by synthetic data. Waymo has higher quality annotated data but less total mileage. Chinese programs (BYD, XPeng) have comparable fleet scale within China but less diverse geographic data. Competitors can and do use simulation, but simulation-trained models have measurable gaps versus real-world trained ones.
2. A deployment loop that compounds. Each new Tesla on the road generates more data, which improves the model, which makes the next generation better, which increases uptake. This is the classical network-effect pattern applied to a physical product.
3. Switching costs that lock in the data advantage. A driver with a Tesla and FSD subscription has workflow habits, trained expectations, and payment relationships that make switching costly.
Where the evidence is genuinely contested:
- Waymo's per-mile safety record on deployed robotaxi miles is, by several measures, better than Tesla's per-mile FSD safety record despite far fewer miles driven. Data quantity is not the only variable.
- HW3 vehicles may not be able to run future versions of FSD, raising questions about whether the "fleet data loop" includes the installed base as firmly as claimed.
- The regulatory pathway to unsupervised autonomy is unsettled. A moat that depends on first-mover regulatory approval may get reshuffled if competitors launch supervised-to-unsupervised faster.
This is what a new-tech moat looks like when the evidence is still being generated. Tesla's moat thesis is not obviously correct or obviously wrong. It is a genuine open question, and the right investor stance is to hold a position sized to the uncertainty rather than to the conviction.
Case Study: Reading Moat Formation in Real Time
Consider three investors looking at Anthropic and OpenAI in January 2026, when both are at roughly $10–20B ARR and racing against each other for the enterprise LLM market.
Investor A compares them by weekly active users. OpenAI has 900M; Anthropic does not disclose but is known to have far fewer. Conclusion: OpenAI has the larger moat. They are wrong, because weekly active users at the consumer level are not the relevant moat metric for an enterprise-API business. The metric matters only if the business you are valuing is consumer-first. Different businesses require different moat signals.
Investor B compares them by revenue. Both are growing fast. Valuations are comparable. Conclusion: the two are roughly interchangeable. They are also wrong, because the composition of revenue reveals different moat structures. Anthropic's enterprise-heavy revenue with accelerating customer count is a pattern that historically compounds for years. OpenAI's consumer-heavy revenue with regulatory overhang (subscription churn, ad-supported search disruption) is a different risk profile.
Investor C reads the behavioral signals. Enterprise customer count doubling in two months at the >$1M tier. Enterprise API market share shifting structurally (Ramp data showing 10% → 65%). Specific use-case leadership (Claude Code 54% share, Claude Code driving 4% of all GitHub public commits). Regulatory positioning (Constitutional AI, Responsible Scaling, PBC structure, healthcare certification). Investor C concludes that Anthropic is building a moat specifically in enterprise infrastructure AI, which is a smaller slice of the total AI TAM than OpenAI's consumer reach but a more defensible one. This is a different bet with different risk/reward, not a "better/worse" comparison.
Investor C is not guaranteed to be correct. But they are the only one making a decision based on signals that reveal moat formation rather than headline metrics that flatter whatever narrative is loudest.
The Five Signals That Tell You a New-Tech Moat Is Real
When you cannot wait 20 years for financial evidence, these are the signals that separate a real moat in formation from a hot category that will commoditize.
1. The customer count is growing AND the spend-per-customer is growing. One of these by itself can be a category tailwind (more customers entering a growing market) or a pricing-power artifact (existing customers paying more). Both together is a switching-cost and ecosystem moat forming in real time. Anthropic's pattern fits this.
2. The product is becoming a standard, not just a product. Claude Code is responsible for 4% of public GitHub commits globally. Anthropic's MCP (Model Context Protocol) is being adopted as a cross-vendor standard for AI tool integration. When a company's technology becomes the default interface for a category, competitive switching costs compound at the protocol layer, not just the product layer.
3. Regulatory and safety positioning becomes a sales advantage. For AI, "we pass enterprise security review" used to be a feature. For the current wave, it is the baseline. The next-layer moat is being first-choice for industries where deployment requires sector-specific compliance (healthcare HIPAA, finance compliance, government). Anthropic's positioning in these is materially ahead of OpenAI and Google.
4. The company can lose at a subcategory and still win the category. Real moats show resilience. OpenAI invented the transformer-based LLM boom and still saw its enterprise share cut in half while revenue kept growing — the category was bigger than the initial leader's moat. The question for any current leader is whether they can survive losing a subcategory (Anthropic losing consumer chat, OpenAI losing coding) without compromising the core moat.
5. Partner and customer decisions point structurally in your direction. When Amazon commits $25B to Anthropic, when Microsoft 365 Copilot integrates Claude alongside OpenAI, when Fortune 10 companies standardize on Claude for enterprise deployment — those are not marketing wins. They are infrastructure-layer bets that compound for years. Partner reach is one of the cleanest moat-formation signals available.
The Common Mistake: Mistaking Growth for Moat
The single most expensive error in new-technology investing is treating fast revenue growth as evidence of a moat.
Every category that becomes large enough to attract public attention also attracts massive capital investment. The fast-growing leader in the early phase is almost always a temporary winner, not a durable one. Cisco in 1998 was growing at 40%+ as the internet built out. Half the names in the Nasdaq 100 of 1999 no longer exist as independent companies today. Fast growth, by itself, is evidence of a category tailwind, not evidence of a moat.
The discipline is to ask, every time: would this growth continue if capital were cut off tomorrow? If the business depends on ongoing massive funding to sustain itself, the moat is unproven. OpenAI is projected to burn $14B in 2026, with an infrastructure commitment of over $1 trillion and no projected positive free cash flow until 2029. That capital dependence is not a criticism — it is a category reality — but it does mean the moat thesis is contingent on continued capital availability. Anthropic's path is directionally similar though with faster revenue growth relative to burn.
The fix is to write down, explicitly, the specific moat hypothesis for any new-tech position you own: which of the four categories, what the behavioral signals are, and what would prove the thesis wrong. If the thesis is "the business is growing fast," that is not a moat hypothesis — that is an extrapolation. Extrapolation does not hold up when category growth rates normalize.
What to Watch
Three habits will turn new-tech moat analysis from speculation into disciplined evaluation.
Track the commitment-depth signals, not just revenue. Customer count at high-spend tiers, percentage of workflow integrated, percentage of commits generated, percentage of engineering teams standardized on the tool, renewal rate, net revenue retention. These signals lead revenue by 6–12 months. Revenue is the output. Commitment depth is the cause.
Read the losing side for signals. Sam Altman declared a "code red" at OpenAI in December 2025 specifically because enterprise API share had shifted. When a competitor publicly restructures around responding to you, that is an acknowledgement from inside the losing company that your moat is real. Read these statements carefully — they often contain concessions that are more revealing than the winning company's marketing.
Pre-commit to kill criteria. For any new-tech position, write down the three observations that would make you exit. For Anthropic: "If enterprise customer growth slows to <10% QoQ for two quarters" or "If Claude Code market share drops below 40%" or "If a major enterprise publicly switches back to OpenAI." For Tesla FSD: "If unsupervised-FSD regulatory approval slips past a specific date" or "If a major OEM reaches competitive per-mile safety numbers at scale." These are not predictions. They are trip-wires. Without them, you will hold too long or exit too early based on whichever direction the price has moved most recently.
Brutal Edge Coverage Integration
This week's framework maps directly onto our coverage:
- Anthropic Private Investor Report — the full new-tech moat decomposition for Anthropic, including the enterprise customer cohort analysis, the regulatory-gated scale thesis, the multi-cloud infrastructure strategy as vertical integration, and the specific scenarios under which the moat either continues compounding or plateaus. Reading this week's framework alongside that report is the cleanest way to see each signal in action on a specific company.
- Physical AI Sector Report — applies the same framework to Tesla's FSD data-network moat, Chinese AV program competitive positioning, and the humanoid robotics category where moat formation is still at the "pre-category" stage. The specific moat-vs-tailwind decomposition for Tesla sits in that report.
- TSLA Deep Dive Rev.2 (BEAF 58/C+) — the score specifically reflects moats that are partially formed and partially unverified. Reading the score alongside this week's framework clarifies which components of the Tesla thesis are durable and which are tailwind-riding.
- NVDA Deep Dive (BEAF 83/B+) — the case where new-tech moats (CUDA ecosystem, developer lock-in, scale of installed base) passed the behavioral-signal tests earlier than most competitors realized. The 83 score reflects that those signals held up across multiple years.
For additional frameworks, see our Deep Dive archive.
Looking Ahead
This week closes the moat module. Over the next three weeks we shift from what makes businesses worth more than their peers to how to actually read public company disclosures — the 10-K, the earnings call, and the proxy statement. These are the documents where real moat-and-valuation analysis actually happens for most investors, and where most retail investors never go. Next week we start with the 10-K, using Tesla's most recent filing as the working example.
For now, sit with this week's lesson. The moat framework still works for new-technology businesses. You just have to learn to read the early behavioral signals instead of waiting for the 20-year financial track record. The investors who master this reading have an edge that does not show up in the Bloomberg terminal — which is exactly why it is still available.
Brutal Edge. Frameworks over forecasts. Signal over noise.
Disclaimer. Brutal Edge is an independent investment research platform. This report is published for educational and informational purposes only and does not constitute investment advice, a recommendation to buy or sell any security, or an offer to transact in any financial instrument. All valuations, forecasts, and opinions are the analyst's own and are subject to change without notice. Past performance does not guarantee future results. Readers should conduct their own due diligence and consult a qualified financial professional before making investment decisions.
Educational content only. Not investment advice. Always do your own research.